A história dos bancos de dados
Antigamente as empresas armazenavam informações em fichas de papel que eram organizadas em arquivos físicos através de pastas. Extrair informações e manter esses arquivos organizado era uma tarefa que exigia um esforço (e custo) maior. Além disso o acesso à informação dependia da localização geográfica dos arquivos. Pouco tempo depois, esses arquivos físicos evoluíram para arquivos digitais. No início, cada entidade (clientes, funcionários, produtos, etc) era um arquivo de dados que eram acompanhados de um “software simples” para manipular os dados do arquivo, que permitiam realizer operações de cadastro, alteração, exclusão e consulta nos arquivos digitais. Essa metodologia conseguiu facilitar a função de consulta de dados, mas ainda tinha problemas de organização como de um arquivo físico.
O “software simples” era um tipo de software conhecido como CRUD (Create, Read, Update e Delete), que realizava operações básicas como cadastro, consulta, atualização e exclusão de registros de um arquivo digital, manipulando uma única entidade.
As entidades precisavam relacionar-se (por exemplo, um produto é fornecido por um fornecedor) e os “softwares simples” para manipular os arquivos digitais começaram a ficar “complexos” para permitir os relacionamentos entre entidades. Então, na década de 60 a empresa IBM investiu fortemente em pesquisas para solucionar estes problemas dos bancos de dados digitais primitivos. Vários modelos de bancos de dados surgiram nesta época, dentre eles os modelos hierárquico e rede.
Em junho de 1970, o pesquisador Edgar Frank “Ted” Codd da IBM, mudou a história dos bancos de dados apresentando o modelo relacional no artigo intitulado “A Relational Model of Data for Large Shared Data Banks”, onde o autor apresentou uma forma de usuários sem conhecimento técnico armazenarem e extraírem grandes quantidades de informações de um banco de dados. Esse artigo foi o grande impulso para a evolução dos bancos de dados, a partir do artigo de “Ted” Codd que os cientistas aprofundaram a ideia de criar o modelo de banco de dados relacional.
Banco de dados relacional
Apesar de ter sido o marco dos bancos de dados relacionais, o artigo de Codd não foi muito explorado no início. Só no final da década de 70 que foi desenvolvido um sistema baseado nas idéias do cientista, o “Sistema R”. Junto com esse sistema, foi criado a Linguagem de Consulta Estruturada (SQL – Structured Query Language) que se tornou a linguagem padrão para bancos de dados relacionais. Embora tenha contribuído para a evolução dos bancos de dados relacionais, o “System R” não foi muito bem sucedido comercialmente, mesmo servindo de base para os sistemas de banco de dados seguintes.
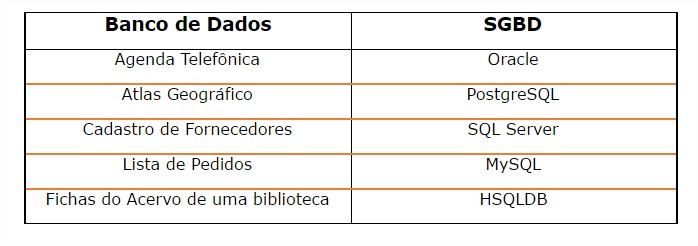
Nos anos 80 surgiram outros bancos de dados, a Oracle apresentou o Oracle 2 e a IBM o SQL/DS (que se tornou DB2), ambos sistemas comerciais de bancos de dados. Na sequência vieram SQL Server, MySQL, DBase III, Paradox, etc.
Bancos de dados hoje
Atualmente existem vários modelos de bancos de dados tais como orientado a objetos, orientado a documentos, etc. Mas o mais comum ainda é o banco de dados relacional. A decisão entre qual modelo de banco de dados utilizar baseia-se no tipo de dados que você pretende armazenar. Por exemplo, se você for armazenar uma grande quantidade de dados em um modelo pequeno é mais indicado utilizar um banco de dados orientado a documentos a um banco de dados relacional. A decisão de projeto vai de acordo com o tipo do dado que se deseja armazenar, não há uma questão de superioridade entre os modelos.